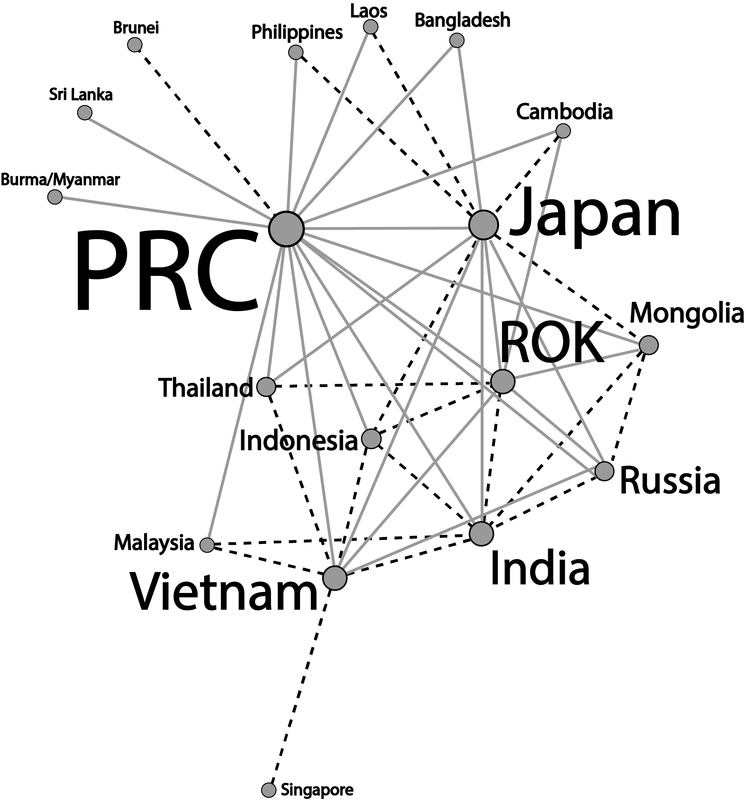
Figure 1. Partnerships in East Asia
*black solid lines: 'strategic partnerships'
*gray dash: any other relationship that uses qualifiers (i.e. 'cooperative,' 'comprehensive,' a mix of both)
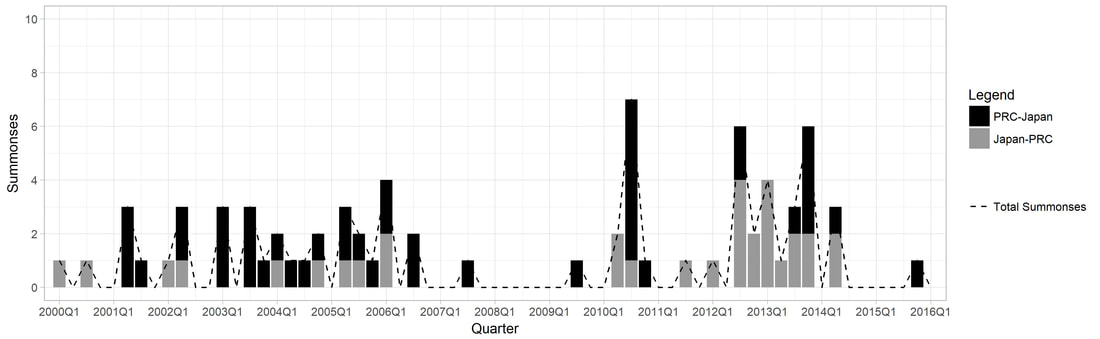
Figure 1.1. Longitudinal Trend in Summonses for Japan and PRC
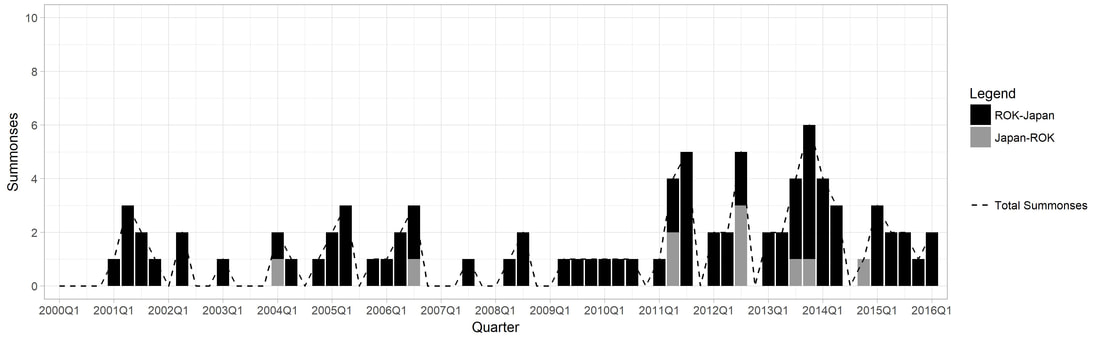
Figure 1.2. Longitudinal Trend in Summonses for Japan and ROK
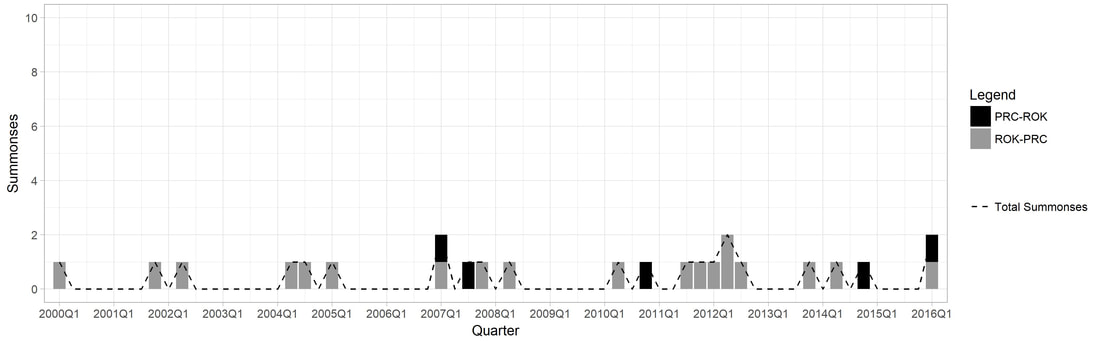
Figure 1.3. Longitudinal Trend in Summonses for PRC and ROK
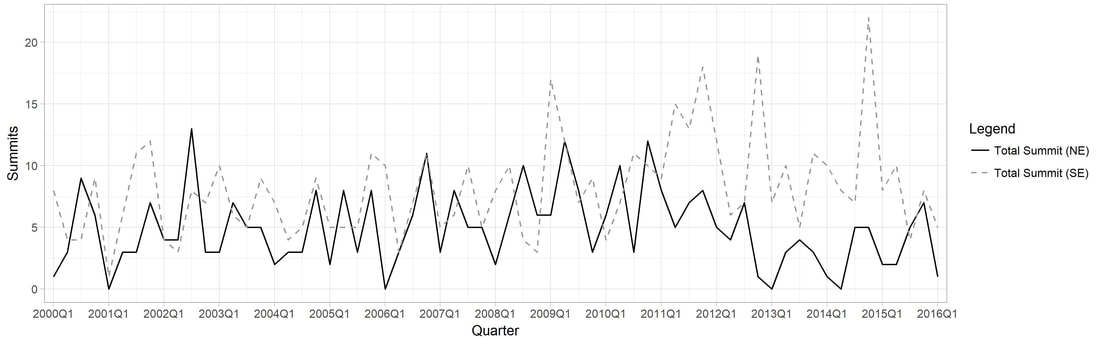
Figure 2. Comparison of Total Summits for Northeast and Southeast Asia
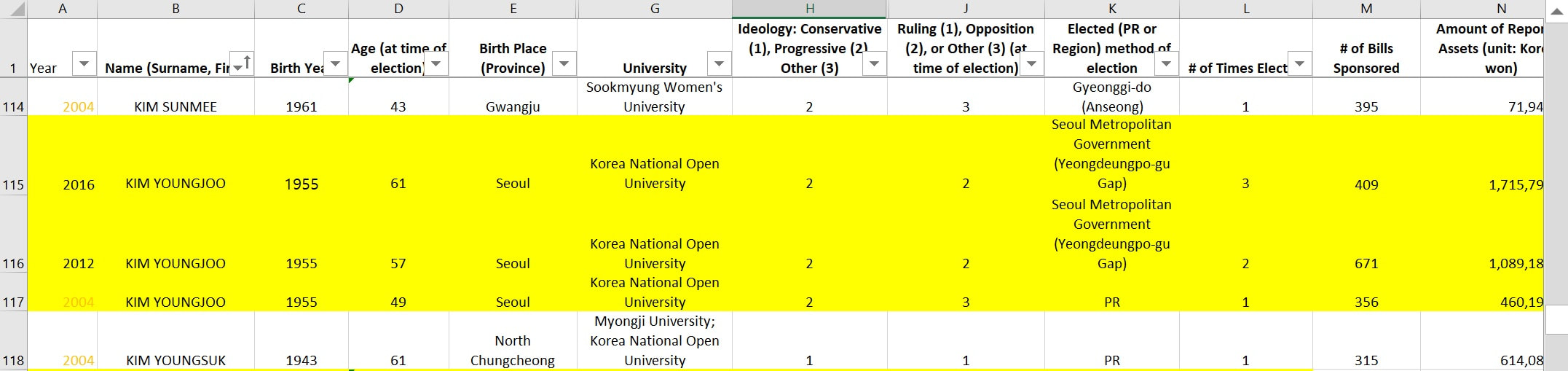
Figure 1. Screenshot of Compiled Data of Female Parliamentarians (1992-2016)
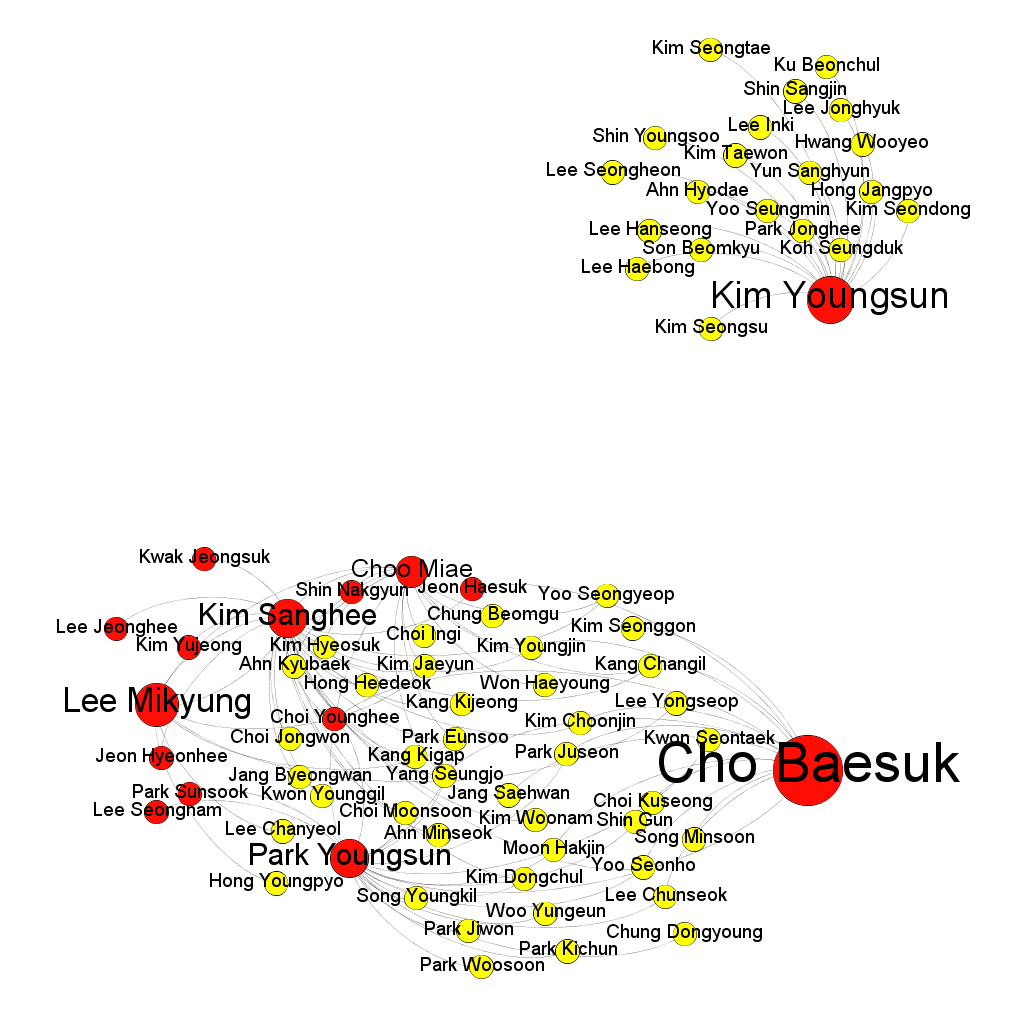
Figure 2. Core Sponsors of Female Power Elites (18th Assembly) *red indicates female, while yellow indicates male
|
1. (Harvard Dataverse) Replication data for: "Why So Many Layers? China's 'State-Speak' and its Classification of Partnerships" Description: The emphasis here is on examining whom states are interacting with (actors), not what they are adhering to (objects). Hence, the purpose of the dataset is to be able to visualize the existing collective habitude of what 'state-speak' looks like in the 18 countries of East/Southeast Asia (as of 2015). 'State-speak' is basically the diverse vocabulary or 'labels' that states give to designate their bilateral relationships (i.e. strategic partnerships, comprehensive partnerships, comprehensive strategic partnerships...). Figure 1 represents a force-directed layout with node and lable proportionality based on the number of degrees (how many neighbors a node have and eigenvector centrality (how many neighbors a node have in addition to how well-connected those neighbors are in the network. 2. Summonses & Summits Database Description: I have collected data on the diplomatic practice of summonses and summits to extract observations about both conflictual and cooperative sides to inter-state interaction in Northeast and Southeast Asia from 2000 to 2016. There are several points of interest that the figures convey- perhaps the most immediate one being that the Japan-PRC and the Japan-ROK dyad is conspicuously more conflictual than the PRC-ROK one (which tracks with both scholarly and policy discourse). Another is that the frequency of total summitry at the foreign policy level in Northeast Asia has decreased over the past several years, especially in light of Southeast Asia. *Note for figures 1.1-1.3.: the legend captures the directionality of the summonses so that the source (or summoning) country is represented by the first country that is listed in the pair, with the target (or summoned) country, listed as the second, as well as the accumulative dyadic total represented by the dash line. 3. South Korean Female Parliamentarian Database Description: I have collated information for all elected South Korean female parliamentarians from the 14th (1992) to the 21st (2020) legislative elections based on the following characteristics- age, birth place, alma mater, ideology, method elected, number of times elected, number of bills sponsored, and total assets. (A screenshot of the information is displayed on the left.) Based on this data, I explore the bill sponsorship networks of female "power elites"- legislators who have been elected three or more times, of which there are only ten from 1992 to 2020. I argue that the bill sponsorship network of these elites differ based on their party affiliation: while the progressive incumbents tend to collaborate more frequently with each other and with other female colleagues due to shared socio-historical institutional spaces on women empowerment, the lack of such legacy for the conservative female lawmakers generates a shallow network of intra-gender sponsorship as well as a more diverse portfolio of sponsors. |
